レッスン8:Pythonによるデータサイエンス入門:NumPy, Pandas, Matplotlib
Contents
レッスン8:Pythonによるデータサイエンス入門:NumPy, Pandas, Matplotlib¶
このレッスンでは、PythonのデータサイエンスライブラリであるNumPyとPandas、およびMatplotlibについて学びます。NumPyは、数値計算を効率的に行うためのライブラリで、多次元配列や行列の操作、数学関数などを提供しています。Pandasは、データ分析を行うためのライブラリで、データフレームという強力なデータ構造を提供しています。Matplotlibはデータを視覚化するためのライブラリです。
目次¶
NumPyの紹介
NumPy配列の基本操作
Pandasの紹介
Pandasのデータ構造
Pandasデータフレームの基本操作
Matplotlibによるデータの視覚化
演習問題
1. NumPyの紹介¶
NumPy(Numerical Pythonの略)は、Pythonで数値計算を効率的に行うためのライブラリです。NumPyは、多次元配列オブジェクトとそれを操作するためのツールを提供します。また、数学関数(sin、cos、expなど)、乱数生成、線形代数操作など、科学計算に必要な機能も提供しています。
NumPyは、Pythonのデータサイエンスエコシステムの基盤となるライブラリで、Pandas、Matplotlib、Scikit-learnなどの他のライブラリがNumPyの配列をデータ構造として使用しています。
NumPyを使用するには、まずライブラリをインポートする必要があります。慣例として、NumPyはnpというエイリアスでインポートされます。
import numpy as np
このコードは、NumPyライブラリをインポートし、それをnpという名前で参照できるようにします。
2. NumPy配列の基本操作¶
NumPyの主要な機能は、n次元配列オブジェクト(通常は1次元や2次元)で、これを使って大量の数値データを効率的に操作できます。
NumPy配列は、numpy.array関数を使用して作成します。以下に、NumPy配列の作成方法を示します。
import numpy as np
a = np.array([1, 2, 3])
print(a)
[1 2 3]
このコードは、1次元のNumPy配列を作成し、その内容を表示します。
NumPy配列は、リストと同様にインデックスを使用して要素にアクセスできます。
import numpy as np
a = np.array([1, 2, 3])
print(a[0])
print(a[1])
print(a[2])
1
2
3
このコードは、NumPy配列の各要素を表示します。
NumPy配列は、リストとは異なり、すべての要素が同じ型でなければならないという制約があります。要素の型は、配列を作成するときに自動的に推定されますが、dtypeパラメータを使用して明示的に指定することもできます。
import numpy as np
a = np.array([1, 2, 3], dtype=float)
print(a)
[1. 2. 3.]
このコードは、浮動小数点数のNumPy配列を作成し、その内容を表示します。
3. Pandasの紹介¶
Pandasは、Pythonでデータ分析を行うためのライブラリです。Pandasは、データフレームという強力なデータ構造を提供し、これを使って大量のデータを効率的に操作できます。
データフレームは、異なる型の列を持つことができる2次元のラベル付きデータ構造で、ExcelのスプレッドシートやSQLのテーブルに似ています。データフレームは、大量のデータを効率的に操作するための多くの機能を提供します。
Pandasを使用するには、まずライブラリをインポートする必要があります。慣例として、Pandasはpdというエイリアスでインポートされます。
import pandas as pd
このコードは、Pandasライブラリをインポートし、それをpdという名前で参照できるようにします。
4. Pandasのデータ構造¶
Pandasは、主にシリーズとデータフレームという2つのデータ構造を提供しています。
シリーズ¶
シリーズは、1次元のラベル付き配列で、任意のデータ型(整数、文字列、浮動小数点数、Pythonオブジェクトなど)を保持できます。軸ラベルは一般的にインデックスと呼ばれます。
シリーズは、以下のように作成できます。
import pandas as pd
s = pd.Series([1, 3, 5, np.nan, 6, 8])
print(s)
0 1.0
1 3.0
2 5.0
3 NaN
4 6.0
5 8.0
dtype: float64
このコードは、シリーズを作成し、その内容を表示します。
データフレーム¶
データフレームは、2次元のラベル付きデータ構造で、異なる型の列を持つことができます。データフレームは、スプレッドシートやSQLのテーブル、またはシリーズオブジェクトの辞書に似ています。
データフレームは、以下のようにして作成できます。
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df)
print(df.head())
print(df.tail(3))
A B C D
2013-01-01 0.915986 1.030965 -0.076324 0.289683
2013-01-02 0.194296 0.714887 0.911403 -0.834647
2013-01-03 -0.188598 -2.413912 -1.897007 1.873434
2013-01-04 -1.155970 0.122258 1.118546 0.097807
2013-01-05 -0.157963 0.944244 0.273364 0.080298
2013-01-06 0.628174 -0.162817 -0.396178 0.005269
A B C D
2013-01-01 0.915986 1.030965 -0.076324 0.289683
2013-01-02 0.194296 0.714887 0.911403 -0.834647
2013-01-03 -0.188598 -2.413912 -1.897007 1.873434
2013-01-04 -1.155970 0.122258 1.118546 0.097807
2013-01-05 -0.157963 0.944244 0.273364 0.080298
A B C D
2013-01-04 -1.155970 0.122258 1.118546 0.097807
2013-01-05 -0.157963 0.944244 0.273364 0.080298
2013-01-06 0.628174 -0.162817 -0.396178 0.005269
このコードは、データフレームを作成し、その内容を表示します。データフレームは、6行4列のランダムな浮動小数点数から作成され、インデックスは日付の範囲(2013-01-01から6日間)、列は’A’、’B’、’C’、’D’のラベルが付けられています。 最後の2行のコードは、データフレームの最初の5行と最後の3行を表示します。
また、データをファイルから読み込むときは以下のコードを実行します。
import pandas as pd
# 'filename.csv'を実際のファイル名に置き換えてください。
df = pd.read_csv('filename.csv')
# DataFrameの最初の5行を表示
print(df.head())
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-6-da6463716485> in <module>
2
3 # 'filename.csv'を実際のファイル名に置き換えてください。
----> 4 df = pd.read_csv('filename.csv')
5
6 # DataFrameの最初の5行を表示
~/.local/lib/python3.6/site-packages/pandas/io/parsers.py in read_csv(filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, squeeze, prefix, mangle_dupe_cols, dtype, engine, converters, true_values, false_values, skipinitialspace, skiprows, skipfooter, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, cache_dates, iterator, chunksize, compression, thousands, decimal, lineterminator, quotechar, quoting, doublequote, escapechar, comment, encoding, dialect, error_bad_lines, warn_bad_lines, delim_whitespace, low_memory, memory_map, float_precision)
686 )
687
--> 688 return _read(filepath_or_buffer, kwds)
689
690
~/.local/lib/python3.6/site-packages/pandas/io/parsers.py in _read(filepath_or_buffer, kwds)
452
453 # Create the parser.
--> 454 parser = TextFileReader(fp_or_buf, **kwds)
455
456 if chunksize or iterator:
~/.local/lib/python3.6/site-packages/pandas/io/parsers.py in __init__(self, f, engine, **kwds)
946 self.options["has_index_names"] = kwds["has_index_names"]
947
--> 948 self._make_engine(self.engine)
949
950 def close(self):
~/.local/lib/python3.6/site-packages/pandas/io/parsers.py in _make_engine(self, engine)
1178 def _make_engine(self, engine="c"):
1179 if engine == "c":
-> 1180 self._engine = CParserWrapper(self.f, **self.options)
1181 else:
1182 if engine == "python":
~/.local/lib/python3.6/site-packages/pandas/io/parsers.py in __init__(self, src, **kwds)
2008 kwds["usecols"] = self.usecols
2009
-> 2010 self._reader = parsers.TextReader(src, **kwds)
2011 self.unnamed_cols = self._reader.unnamed_cols
2012
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader.__cinit__()
pandas/_libs/parsers.pyx in pandas._libs.parsers.TextReader._setup_parser_source()
FileNotFoundError: [Errno 2] No such file or directory: 'filename.csv'
‘filename.csv’はデータファイルの名前に置き換えてください。
read_csv()関数はDataFrameを返します。head()関数はデータフレームの最初の5行を返すので、データが正しくロードされたかを確認するために使用できます。
なお、read_csv()関数にはデータの読み込み方法を調整するための多くのオプションがあります。例えば、delimiterパラメータを使用してファイルで使用される区切り文字を指定したり(デフォルトは,(カンマ))、index_colパラメータでインデックスとして使用する列を指定したりできます。全てのオプションについてはpandasのドキュメンテーションを参照してください。
5. Pandasデータフレームの基本操作¶
データの統計情報¶
データフレームの統計情報を表示するには、describeメソッドを使用できます。これにより、各列の平均、標準偏差、最小値、最大値などが表示されます。
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df.describe())
A B C D
count 6.000000 6.000000 6.000000 6.000000
mean -0.142724 0.629523 0.307102 -0.408176
std 0.687221 1.636708 0.743264 1.181161
min -1.093015 -1.605881 -0.732758 -2.014825
25% -0.532254 -0.251523 -0.009172 -1.353475
50% -0.207612 0.465999 0.384860 0.198525
75% 0.415615 1.623728 0.420697 0.419382
max 0.669008 2.932083 1.513522 0.546527
このコードは、データフレームの統計情報を表示します。
また、必要な列のみ、または行のみを表示することもできます。
# 列Aのみを表示
print(df['A'])
# 列AとBのみを表示
print(df[['A', 'B']])
# 列Aが0以上の行を表示
print(df[df['A'] > 0])
2013-01-01 -0.619830
2013-01-02 -1.093015
2013-01-03 0.669008
2013-01-04 -0.269527
2013-01-05 -0.145697
2013-01-06 0.602719
Freq: D, Name: A, dtype: float64
A B
2013-01-01 -0.619830 -0.205091
2013-01-02 -1.093015 1.785940
2013-01-03 0.669008 -1.605881
2013-01-04 -0.269527 1.137090
2013-01-05 -0.145697 -0.267000
2013-01-06 0.602719 2.932083
A B C D
2013-01-03 0.669008 -1.605881 -0.137989 0.435934
2013-01-06 0.602719 2.932083 -0.732758 0.027324
データのソート¶
データフレームのデータをソートするには、sort_valuesメソッドを使用できます。
import pandas as pd
import numpy as np
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
print(df.sort_values(by='B'))
A B C D
2013-01-02 0.001472 -1.895646 -0.533427 0.706643
2013-01-03 0.642805 -0.785847 -0.110950 -0.793293
2013-01-04 -1.180240 -0.753428 0.868489 -0.603261
2013-01-06 0.015827 -0.278565 0.862782 0.194919
2013-01-05 1.383250 -0.030530 -0.394998 -0.928567
2013-01-01 1.568962 1.336813 0.281183 0.112790
このコードは、’B’列の値に基づいてデータフレームをソートし、その結果を表示します。
6. Matplotlibによるデータの視覚化¶
ここでは、Pythonのmatplotlibライブラリを使用してデータを視覚化する例を示します。
import matplotlib.pyplot as plt
# データを作成
heights = [170, 160, 175, 180, 155]
weights = [60, 55, 70, 80, 50]
# 散布図を作成
plt.scatter(heights, weights)
plt.xlabel('Height (cm)')
plt.ylabel('Weight (kg)')
plt.title('Height vs Weight')
plt.show()
上の図は簡単な散布図をMatplotlibで表示したものです。
Matplotlibには他にも様々なグラフ表示方法があります。以下のスクリプトでは、4つのサブプロットを作成しています。最初の一つは指数減衰関数の折れ線グラフ、2つ目は同じデータの散布図、3つ目は5つのカテゴリとそれぞれの値を示す棒グラフ、最後の一つは正規分布のランダムな数値のヒストグラムです。それぞれのプロットにはプロットの種類、x軸ラベル、y軸ラベルが付けられています。
# グラフの軸に日本語を使うために必要な処理
!pip install japanize-matplotlib
Requirement already satisfied: japanize-matplotlib in /usr/local/lib/python3.10/dist-packages (1.1.3)
Requirement already satisfied: matplotlib in /usr/local/lib/python3.10/dist-packages (from japanize-matplotlib) (3.7.1)
Requirement already satisfied: contourpy>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->japanize-matplotlib) (1.1.0)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.10/dist-packages (from matplotlib->japanize-matplotlib) (0.11.0)
Requirement already satisfied: fonttools>=4.22.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->japanize-matplotlib) (4.40.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->japanize-matplotlib) (1.4.4)
Requirement already satisfied: numpy>=1.20 in /usr/local/lib/python3.10/dist-packages (from matplotlib->japanize-matplotlib) (1.22.4)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->japanize-matplotlib) (23.1)
Requirement already satisfied: pillow>=6.2.0 in /usr/local/lib/python3.10/dist-packages (from matplotlib->japanize-matplotlib) (8.4.0)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/local/lib/python3.10/dist-packages (from matplotlib->japanize-matplotlib) (3.1.0)
Requirement already satisfied: python-dateutil>=2.7 in /usr/local/lib/python3.10/dist-packages (from matplotlib->japanize-matplotlib) (2.8.2)
Requirement already satisfied: six>=1.5 in /usr/local/lib/python3.10/dist-packages (from python-dateutil>=2.7->matplotlib->japanize-matplotlib) (1.16.0)
import matplotlib.pyplot as plt
import japanize_matplotlib
import numpy as np
# データを作成
x = np.linspace(0, 5, 100)
y = np.exp(-x)
z = np.random.normal(size=200)
categories = ['A', 'B', 'C', 'D', 'E']
values = [7, 10, 5, 8, 6]
# 図を作成し、2x2のグリッドのサブプロットを設定
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(10, 10))
# 折れ線グラフ
ax1.plot(x, y)
ax1.set_title('折れ線グラフ')
ax1.set_xlabel('x')
ax1.set_ylabel('exp(-x)')
# 散布図
ax2.scatter(x, y)
ax2.set_title('散布図')
ax2.set_xlabel('x')
ax2.set_ylabel('exp(-x)')
# 棒グラフ
ax3.bar(categories, values)
ax3.set_title('棒グラフ')
ax3.set_xlabel('カテゴリー')
ax3.set_ylabel('値')
# ヒストグラム
ax4.hist(z, bins=20)
ax4.set_title('ヒストグラム')
ax4.set_xlabel('値')
ax4.set_ylabel('頻度')
# レイアウトを調整して見栄えを良くする
plt.tight_layout()
# 図とそのサブプロットを表示
plt.show()
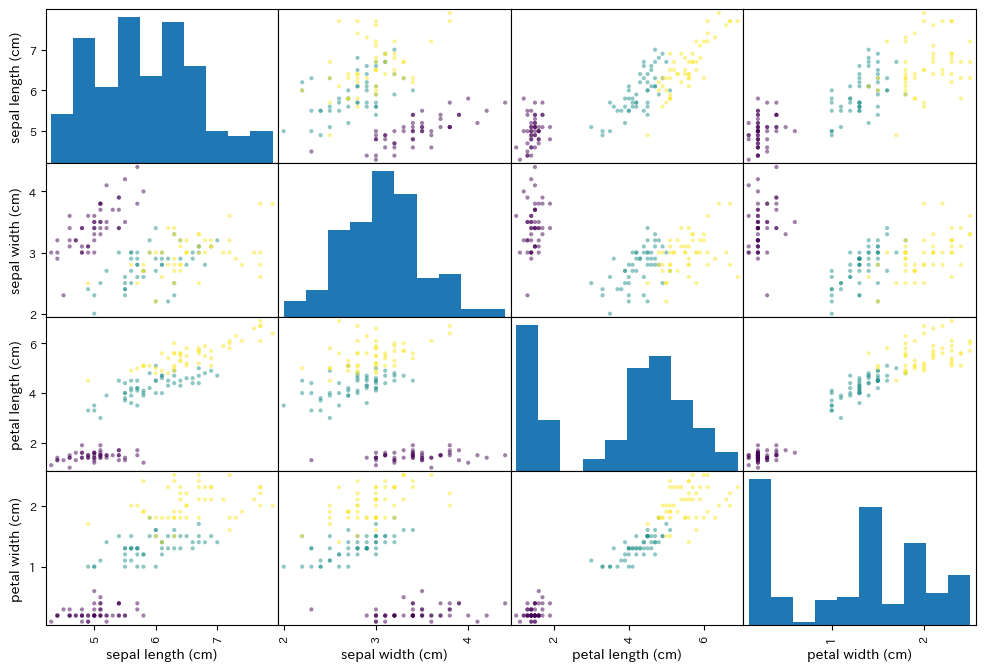
また、Pandasのデータフレームをプロットすることもできます。 例として、Iris(アヤメ)データをデータフレームに変換してプロットした例を示します。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# アヤメデータの読み込みとデータフレームへの変換
iris = load_iris()
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
# 目的変数(アヤメの種類)をDataFrameに追加
iris_df['species'] = iris.target
# 特徴量のペアごとの散布図を描く
pd.plotting.scatter_matrix(iris_df.iloc[:, :4], figsize=(12, 8), c=iris_df['species'])
plt.show()
演習問題¶
以下の演習問題を解いて、NumPyとPandasの基本的な使用方法を理解しましょう。
NumPyを使用して、1から10までの数値を持つ1次元配列を作成してください。
上記の配列の要素の平均値を計算してください。
Pandasを使用して、以下のデータを持つデータフレームを作成してください。
列名:’A’, ‘B’, ‘C’, ‘D’
行名:’2023-01-01’, ‘2023-01-02’, ‘2023-01-03’, ‘2023-01-04’, ‘2023-01-05’
データ:任意の数値
上記のデータフレームの統計情報を表示してください。
上記のデータフレームを’A’列の値でソートしてください。
ヒント:
NumPy配列の作成:
np.array([1, 2, 3, ..., 10])平均値の計算:
np.mean(array)Pandasデータフレームの作成:
pd.DataFrame(data, index=index, columns=columns)統計情報の表示:
df.describe()データのソート:
df.sort_values(by='A')
# 演習問題1, 2
# 以下にコードを書いてみましょう
# 演習問題3-5
# 以下にコードを書いてみましょう